
ICLR 2019에서 발표된 “DARTS: Differentiable Architecture Search” 논문을 읽고 내용을 공유합니다.
DARTS: Differentiable Architecture Search
- Neural Architecture Search (NAS) 연구에 대해, 기존에는 search space가 미분 불가능하다는 문제점 때문에 RL 기반으로만 연구가 진행었는데,
- DARTS는 search space를 미분 가능하게 정의하고 여기에 MAML의 최적화 방식과 동일한 bilevel optimization을 도입하여 gradient descent 기반의 NAS를 가능하도록 만들었음
Algorithm
- Differentiable archtecture search: 논문에서 정의한 bilevel optimization 식을 통한 가중치 $\alpha$ 최적화 수행
- Discretization step: $\alpha$와 $k$ 기반으로 필요 없는 operation edge 제거
- Retraining for the top-$k$ strongest operations: 남은 operation edge에 대해 처음부터 다시 학습 수행
Methodology
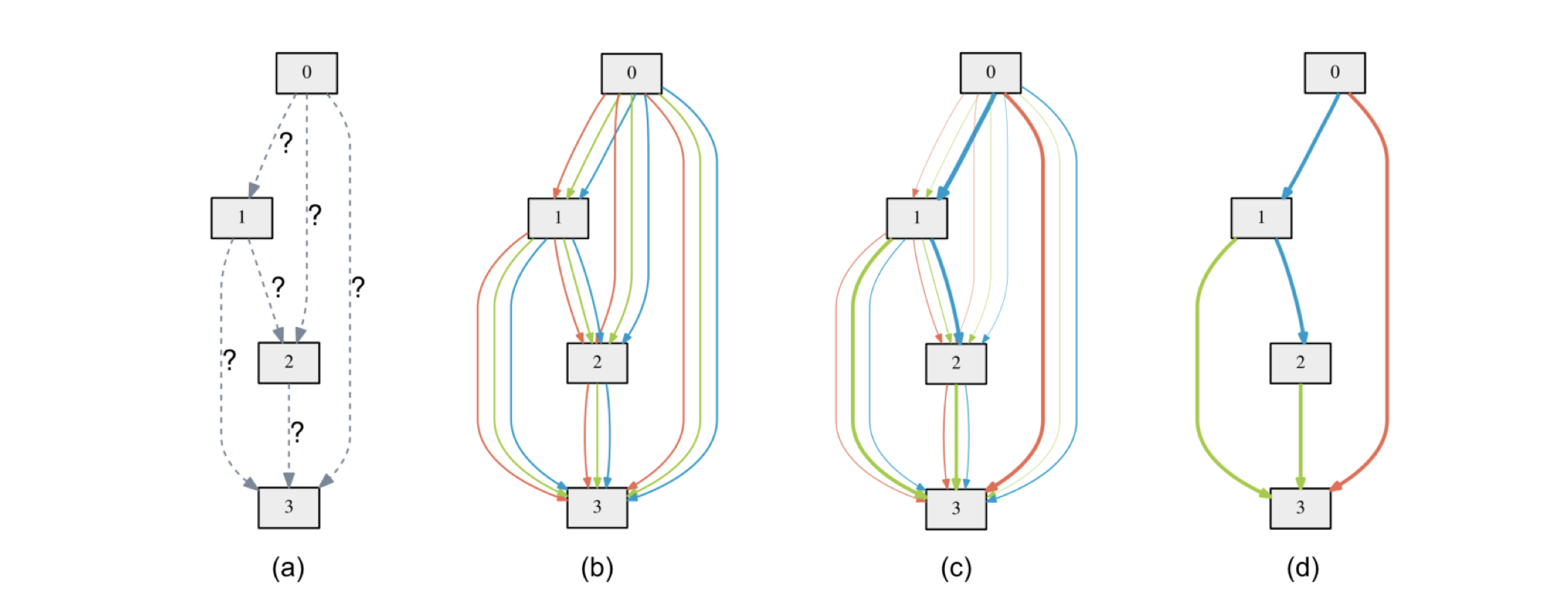
- (a)의 형태면 candidate operations가 discrete한 set 형태로 정의되기 때문에 미분이 불가능한데, (b)의 형태로 수정 후에 각 operation edege에 $\alpha$라는 가중치를 달고 다음 node에 전달되기 전에 softmax function을 거치도록 형태를 변형하면 모든 candidate operations가 continuous한 형태로 연결되어 있기 때문에 미분이 가능해짐
- 여기서 우리의 목표는 $\alpha$를 최적화하는 것이며, objective는 아래와 같이 설정이 가능함
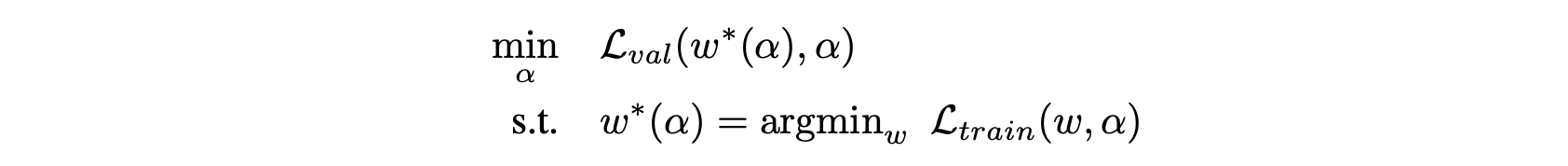
- $\alpha$를 validation loss 기반으로 최적화하기 위해서는 $w$가 결정되어있어야 하며, $w$를 train loss 기반으로 최적화하기 위해서는 $\alpha$가 결정되어있어야 함. 본 논문은 이러한 nested formulation을 bilevel optimization을 통해서 최적화 함

- Bilevel optimization 뿐만 아니라, traning set + validation set을 합친 데이터 셋을 가지고 $\alpha, w$에 대한 coordinate descent와 SGD도 각각 수행하였는데, 성능은 bilevel optimization이 제일 좋았다고 함. 이에 대해 저자들은, 아마 $\alpha$를 training set이 포함된 데이터를 가지고 직접 최적화하였기 때문에 overfitting이 발생했을 것이라고 가정하였음