
Vision transformer와 DINO 논문에 대해, 관련 자료를 읽고 내용을 공유합니다.
Vision Transformer
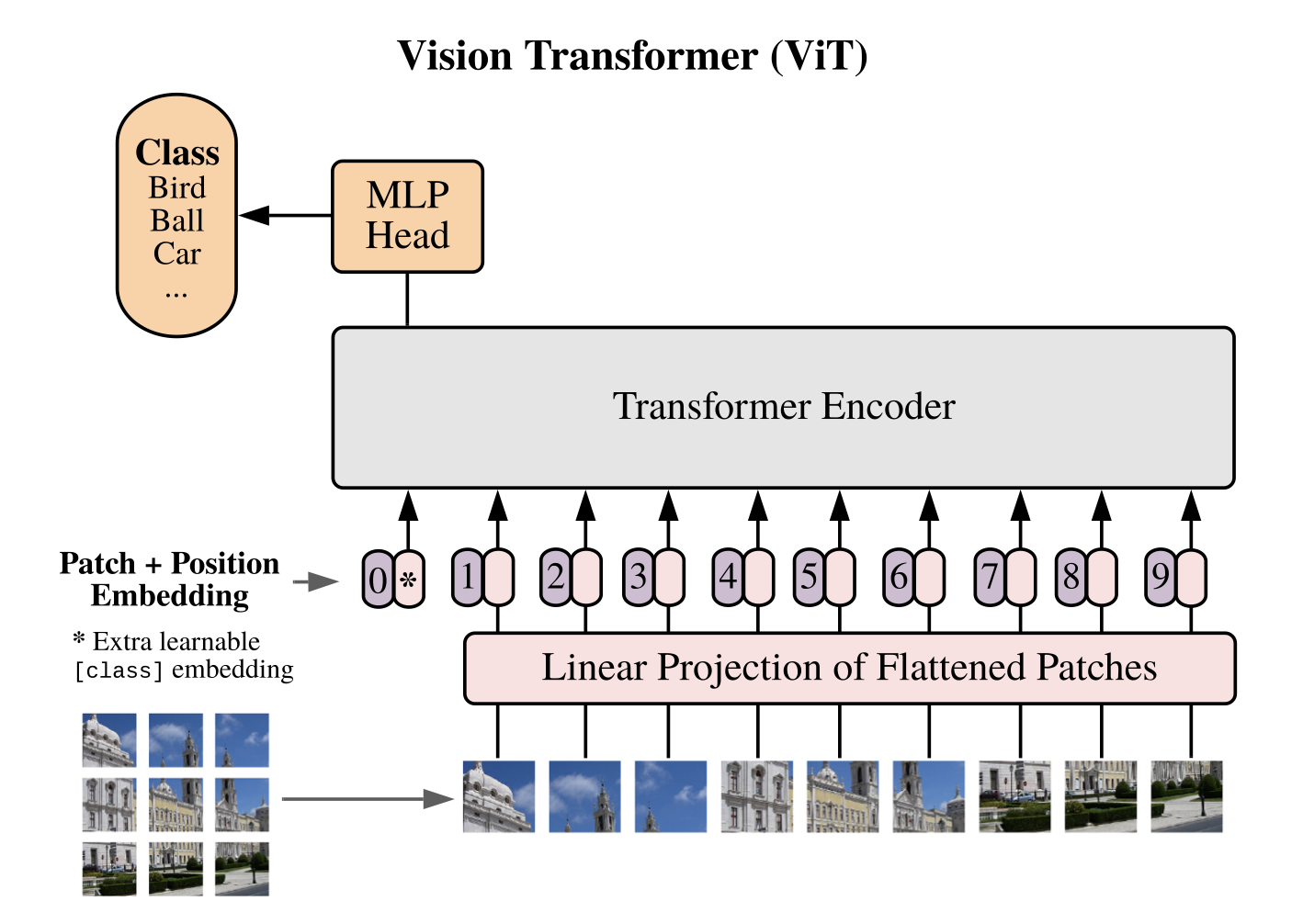
Taken from Dosovitskiy, Alexey, et al.
- 전체 이미지를 16 x 16 size의 patch로 절단. 예를 들어 48 x 48 이미지라면 9개의 patch로 나뉨
- “ViT-Base/16” model에서 16이 의미하는 것이 patch size임
- 각각의 patch를 평탄화(16 x 16 x 3 = 768) 한 뒤에, 워드 임베딩을 만드는 것 처럼 linear projection을 통해 embedding vector의 형태로 변환
- 해당 embedding vector에, BERT와 동일하게 CLS 토큰과 position embedding을 추가함. 이 둘은 learnable parameter 임
- CLS 토큰은 patch embedding과 동일한 사이즈이며, 9개의 patch embedding들과 concat 함
- position embedding은 총 9 + 1 = 10개로, patch embedding에 합(+)해주는 형태로 구성
- 각 embedding vector를 하나의 워드 토큰으로 여겨, transformer의 입력으로 전달
- BERT와 동일하게, CLS 토큰의 최종 출력이 해당 이미지의 output class라고 가정. 따라서 transformer 출력 단에서 CLS의 embedding이 어떻게 변했는지 확인하여 inference 수행
DINO (Self-distillation with no labels)
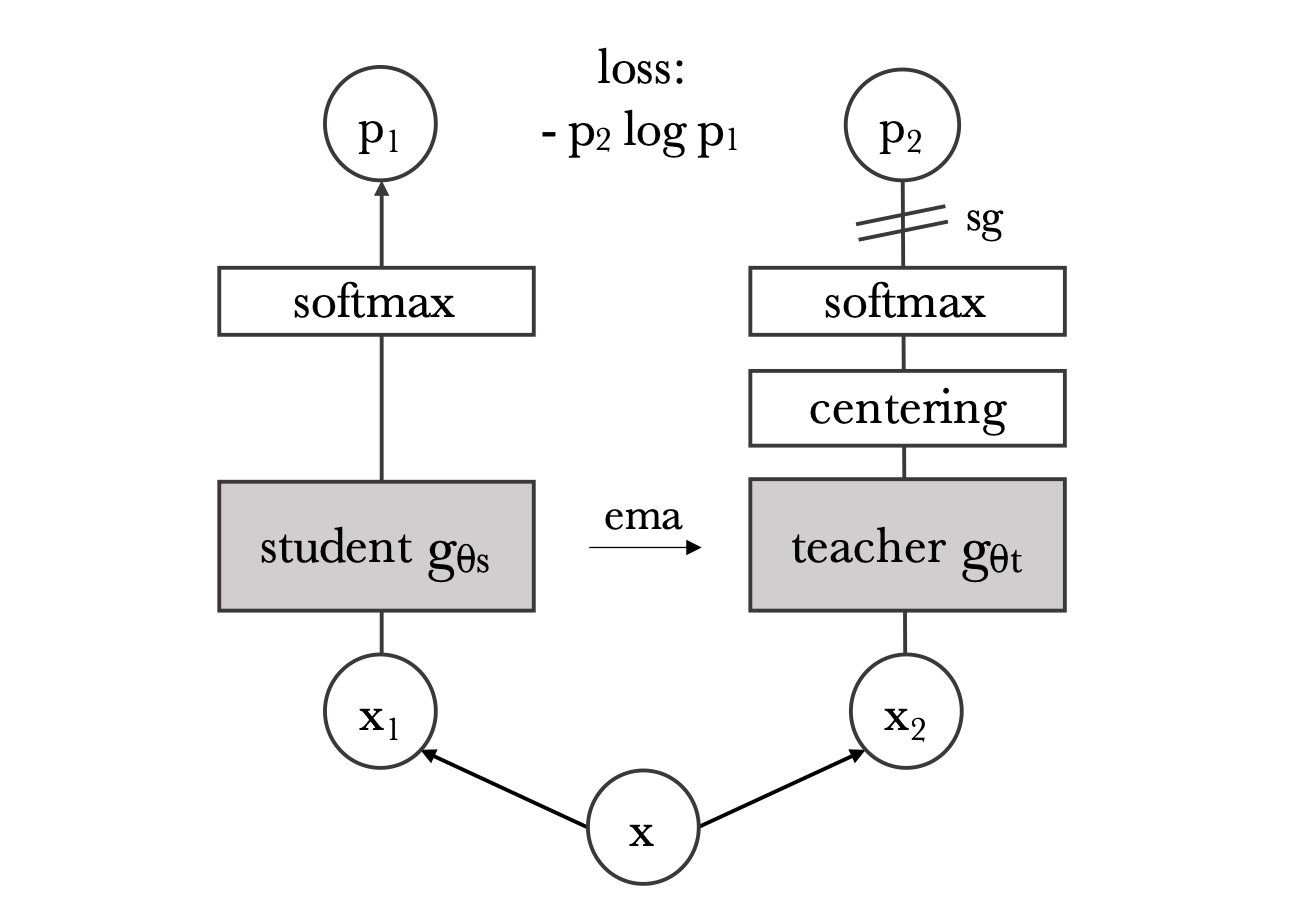
Taken from Caron, Mathilde, et al.
- ViT를 BYOL 의 manner로 학습
- BYOL과 달리 normalized embedding의 L2 distance를 사용하지는 않고, $p_2 \log p_1$ 형태의 cross entropy loss 사용
References
- Advancing the state of the art in computer vision with self-supervised Transformers and 10x more efficient training
- Dosovitskiy, Alexey, et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” International Conference on Learning Representations. 2021.
- Caron, Mathilde, et al. “Emerging properties in self-supervised vision transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
- Yanick Kilcher, “DINO: Emerging Properties in Self-Supervised Vision Transformers (Facebook AI Research Explained)"
- https://github.com/facebookresearch/dino