
Summary

-
2022년 2월 소니 AI가 개발한 자동차 경주 AI가 네이처 표지를 장식했음. 게임 이름은 그란 투스리모 스포츠임.
-
인공지능 이름은 GT Sophy. Model free, off-policy deepRL을 이용했음. Distributional SAC과 비슷하지만 value backup 과 target functions가 다른 QR-SAC을 이용했다고 함.
-
게임의 리얼리즘 때문에 생각보다 어려웠다고 함. 또한 규정화되어 있지 않은 스포츠맨십을 지키며 너무 공격적이지도 소극적이지도 않게 플레이 하기 위한 보상 체계를 만드는 것이 힘들었다고 함.
-
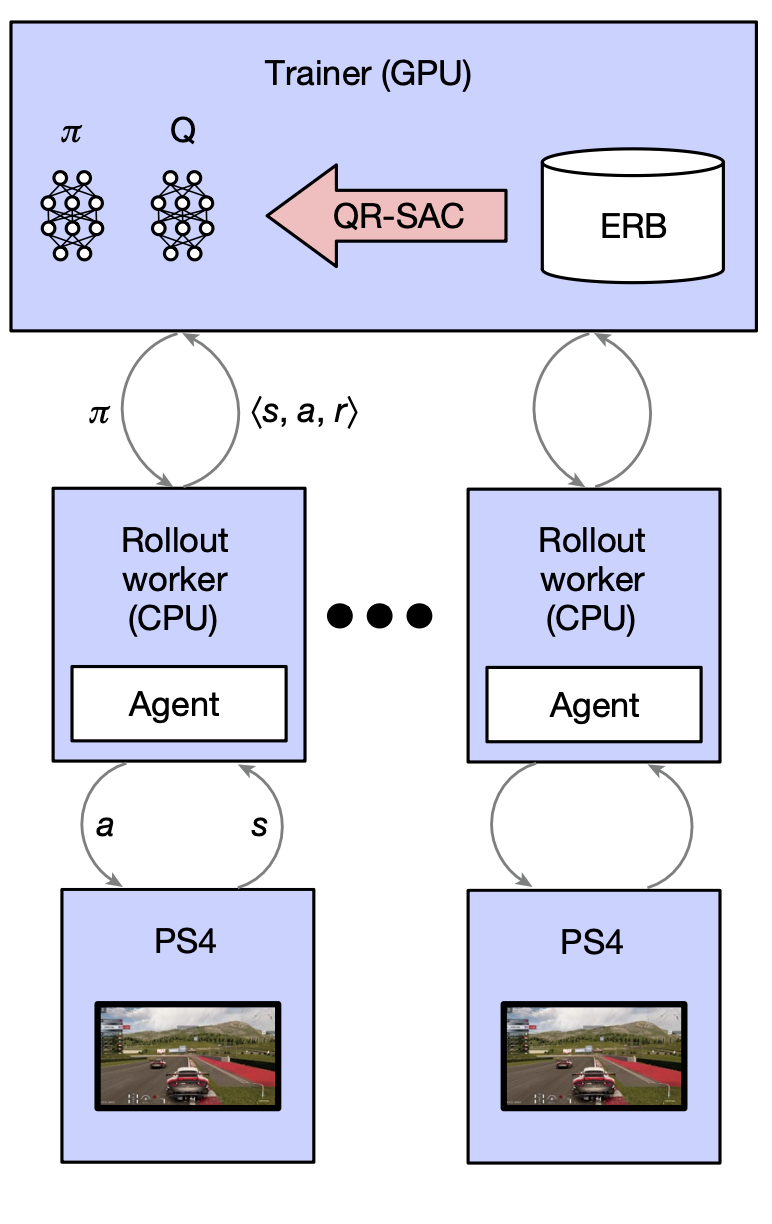
학습 방법: PS4에서 실행되는 GT인스턴스를 제어하는 rollout worker에게 트레이닝 시나리오를 배포하면 각 agent는 가장 최근 policy의 사본을 실행시키고 action을 전송함. 비동기적으로 다음 프레임을 계산해 새로운 상태를 알아냄. State, action, reward 튜플을 ERB에 저장함. 트레이너는 policy를 업데이트하기 위해 ERB를 샘플링함.
Comments
-
강화학습을 이용해 게임에 적용시키는 경우가 점점 늘어나는 것 같음. 적용시키기 좋고, 흥미로우며 이슈도 되기 때문이라 생각함. 개인적으로도 해 보고 싶다는 생각이 들었음.
-
AI vs 사람 구도의 실험에서는 AI와 사람 간 공평성을 위한 적절한 방법들이 고려되어야 함. 예를 들어 알파스타의 경우 평균 APM에 제한을 두었지만 중요한 교전 상황에 압도적인 순간 APM을 보이며 승리했음. 사람의 경우 APM이 모두 의미 있는 동작을 뜻하지 않으므로 실제 차이는 더 컸었다 해석할 수 있음. 해당 실험에서도 여러 사항을 고려하여 제약을 두었음. 논문의 Fairness versus humans에서 찾아볼 수 있음.
-
개발진들이 이런 연구를 하는 이유는 사람과 싸워 이기는 AI를 만들기 위함이 아니라 사람을 더 잘 이해하고, 더 재미있으며 흥미로운 탐험과 새로운 경험을 사용자에게 제공하기 위함이라 함.
-
연구의 의미를 항상 생각하는 것이 중요함을 다시 한 번 느꼈음. 새로운 방법과 좋은 성능 자체도 의미있지만 이들이 앞으로의 연구와 우리의 삶에 어떤 긍정적인 역할을 할지 깊게 생각한다면 더 좋을 것 같다는 생각을 했음.